How to Run a Distributed Software Team Across Time Zones Without Losing Velocity
Time zones don't kill distributed team velocity — blocking dependencies, poor handoff quality, and sync-first cultures do. Here's the operational playbook for shipping fast with a global dev team.
Key Takeaways
- 1Running a distributed software team across time zones doesn't require compromising velocity — it requires redesigning your processes so that async work carries the load and sync time is used deliberately.
- 2The biggest velocity killers aren't time zones themselves — they're blocking dependencies, poor PR quality, and synchronous processes that were designed for co-located teams and never adapted.
- 3Git workflow discipline, code review SLAs, async-first sprint ceremonies, and a well-managed overlap window are the four levers that determine whether a distributed team ships fast or stalls.
The most common thing CTOs say when they're evaluating an offshore development team for the first time is: "I'm worried about the time zone gap."
It's a reasonable concern, but it's usually the wrong diagnosis. After building and running software development teams across multiple time zones — with clients in the US, UK, and Australia working with Mumbai-based engineers — we've learned that time zones are rarely the actual problem. The problem is almost always process.
Teams that struggle with distributed development are usually teams that took their co-located workflows and tried to run them remotely. Daily standups became awkward video calls at inconvenient hours. PR reviews sat waiting for someone to wake up. Architectural decisions that needed conversation got blocked for days.
Teams that ship well across time zones built their processes for distribution from the start. They treat async work as the default and sync time as a scarce resource to be spent deliberately. The result, counterintuitively, is often better engineering hygiene than co-located teams ever had.
This post is the operational playbook. Git workflows, code review cadence, sprint ceremonies, async communication standards — what actually works when your team spans 9+ hours of timezone difference.
Why most distributed teams lose velocity (and it's not what you think)
Before the playbook, it's worth being precise about what actually kills velocity in distributed teams. The answer is almost always one of three things:
- Blocking dependencies — a developer in Mumbai can't proceed until they get an answer from someone in San Francisco who won't be online for 8 hours.
- Poor handoff quality — code, context, and decisions aren't documented well enough for the next person to pick up without a live conversation.
- Sync-first culture — standups, planning sessions, and design reviews are all scheduled calls, which means a timezone mismatch creates an entire day of lost momentum.
Notice what's not on that list: the time zone itself. A 9.5-hour difference between Mumbai and London is a fact. How you structure work around that fact is a choice. The teams that make the right choices — async-first, documentation-heavy, PR discipline — routinely outperform co-located teams that work in the same office but have poor engineering culture.
The async-first mindset shift
The single most important shift for distributed teams is accepting that asynchronous communication is not a compromise — it's an upgrade.
In a co-located office, a lot of decision-making happens informally: someone taps a colleague on the shoulder, a question gets answered in 30 seconds, and development proceeds. This feels fast. But it produces teams where critical context lives in people's heads rather than in documentation, where the same questions get asked repeatedly, and where onboarding a new engineer takes months because tribal knowledge is everywhere.
Async-first teams are forced to externalise that knowledge. Decisions get written down. PRs have context, not just code. Architecture discussions happen in documents with comment threads, not in conversations that 80% of the team wasn't present for. This is initially more work. Six months in, it's a compounding advantage.
The practical rule is this: if a question, decision, or piece of context would be useful to anyone else on the team — now or in the future — it doesn't go in a direct message. It goes somewhere visible and searchable.
Git workflows that work across time zones
Git is where the rubber meets the road for distributed engineering. The workflow choices you make here determine whether your team ships or stalls.
Branch strategy: trunk-based with short-lived feature branches
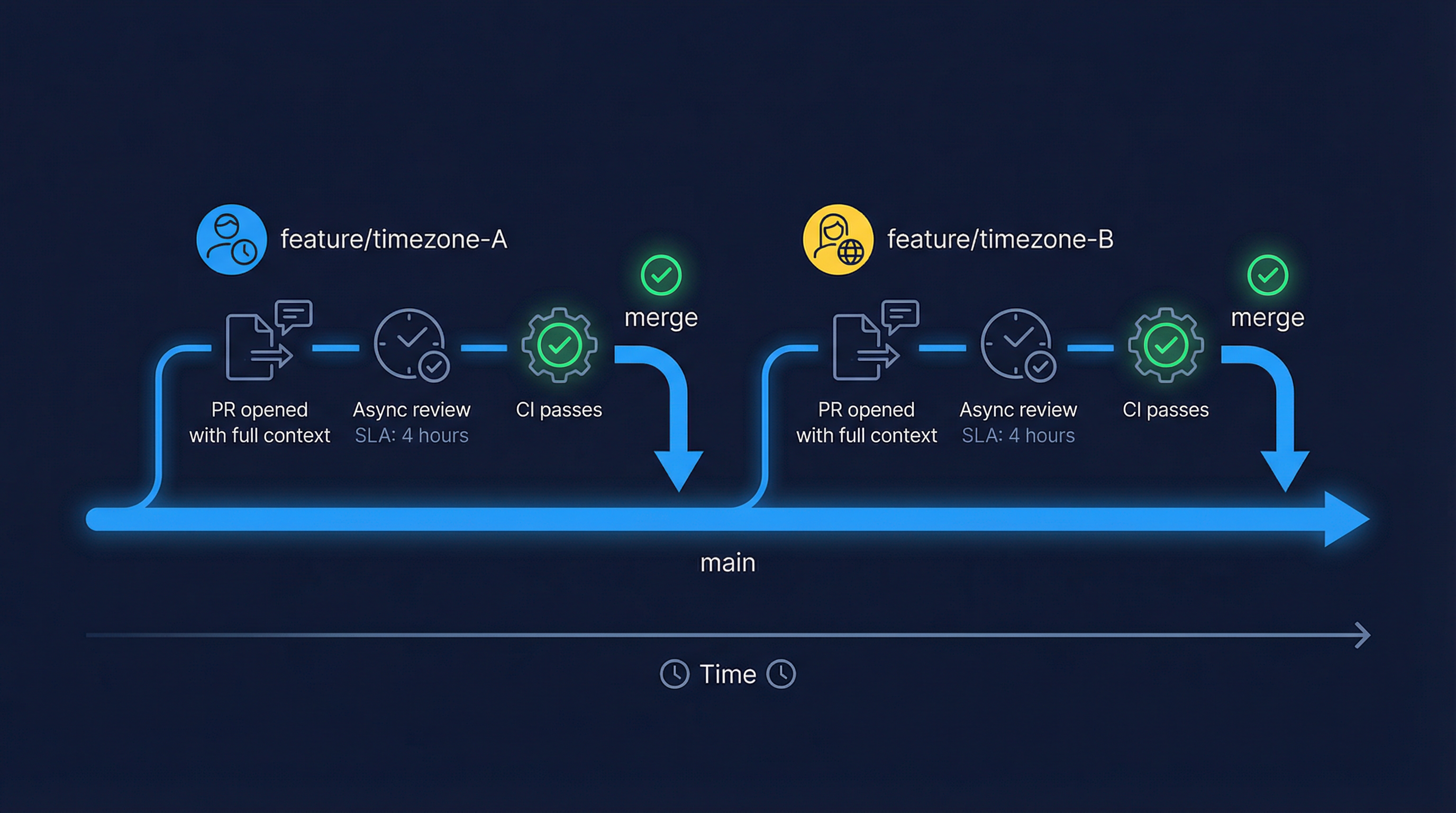
Long-lived feature branches are a distributed team's enemy. The longer a branch lives, the more diverged it becomes from main, and the more painful the eventual merge. For distributed teams, we strongly prefer trunk-based development: engineers work in short-lived feature branches (ideally merged within 1-2 days), with feature flags used to hide unfinished functionality from production.
This keeps the merge surface small, reduces the chance of a review becoming a multi-day back-and-forth, and means the main branch is always close to deployable.
PR discipline: small, self-contained, and context-rich
The most common source of review delays in distributed teams is PRs that are too large. A 2,000-line PR opened at 6pm Mumbai time will not get reviewed before the engineer goes to sleep — and by the time feedback arrives the next morning, context has been lost.
The discipline we enforce is simple: PRs should ideally be under 400 lines of meaningful change (not counting generated files, migrations, or boilerplate). If a feature requires more, it gets broken into a stack of sequential PRs, each reviewable independently.
Every PR needs: a description of what it does and why, a note on what to look for in review, any context the reviewer needs that isn't obvious from the diff, and a test plan or evidence that the change works. This feels like overhead until you've been on the receiving end of a well-written PR at 9am that you can review in 15 minutes without a live conversation.
Commit messages as documentation
In distributed teams, the git log is a communication channel. Commit messages should explain why a change was made, not just what changed. "Fix bug" tells the next engineer nothing. "Fix race condition in auth token refresh — token could expire between check and use when requests arrived within 200ms of each other" tells them everything they need to understand the change without a conversation.
This sounds fastidious. It becomes essential the first time someone in a different timezone needs to understand a regression and the original author is asleep.
Code review cadence: SLAs, not availability
Code review is where distributed teams most commonly create blocking dependencies. An engineer opens a PR and waits. The reviewer is in a different timezone. Hours pass. The engineer moves on to something else, loses context, and the review-respond-revise loop stretches across multiple days.
The solution is a review SLA — a defined expectation that every PR will receive initial review within a set window (we use 4 hours during the reviewer's working day). This isn't always achievable, but naming the expectation changes the culture. Reviews stop being "something I'll get to when I have a free moment" and become a first-class responsibility.
Pair this with clear ownership: every PR has a designated reviewer assigned at open time, not left for someone to self-select. If the designated reviewer can't get to it within the SLA, it's their responsibility to reassign — not the author's responsibility to chase.
For teams with significant timezone separation, consider structuring reviews to flow with the sun: Mumbai engineers review PRs opened by US engineers at end-of-day, so feedback arrives when the US team starts their morning. US engineers review Mumbai PRs in the first hour of their day. Two rounds of review happen within a single 24-hour period without either team changing their working hours.
Sprint ceremonies redesigned for distribution
Most distributed teams inherit sprint ceremonies designed for co-located offices. Daily standups become awkward video calls where half the team is at 8pm and the other half is at 7am. Planning sessions run long because the timezone math means extending them is genuinely painful. Retrospectives get skipped because scheduling them across zones takes more coordination than they seem worth.
The better approach is to redesign each ceremony from first principles for a distributed context.
Daily standup: async by default, sync for exceptions
The traditional standup was designed to surface blockers quickly and ensure everyone knew what the team was working on. Both goals can be achieved asynchronously. Each engineer posts a brief update at the start of their workday — what they completed, what they're working on today, and any blockers. A simple Slack channel or a tool like Geekbot works fine.
The live standup is reserved for situations where there's actually something that benefits from real-time discussion: a blocker that needs immediate resolution, a scope question that's blocking multiple people, or a critical bug in production. These happen less often than daily.
Sprint planning: pre-work over live sessions
The pain of a two-hour planning session across a 9-hour timezone gap is real. The solution is shifting most of the cognitive work out of the live session. The product owner circulates the proposed sprint backlog 24 hours in advance, with ticket descriptions detailed enough for engineers to come with questions and estimates. The live planning session becomes a 45-minute alignment call — questions answered, estimates confirmed, priority clarified — rather than a discovery session.
This requires product and engineering discipline in ticket writing. That discipline pays off in faster planning and clearer execution throughout the sprint.
Retrospectives: written first, discussed second
Retrospectives work well in a distributed context when they're run as two-phase exercises. Phase one: everyone submits their retrospective notes asynchronously in a shared document — what went well, what didn't, what they'd change. Phase two: a 30-minute live session to discuss themes that emerged, not to generate them from scratch.
This produces more thoughtful input (people have time to reflect, not just react) and a shorter, more focused live session.
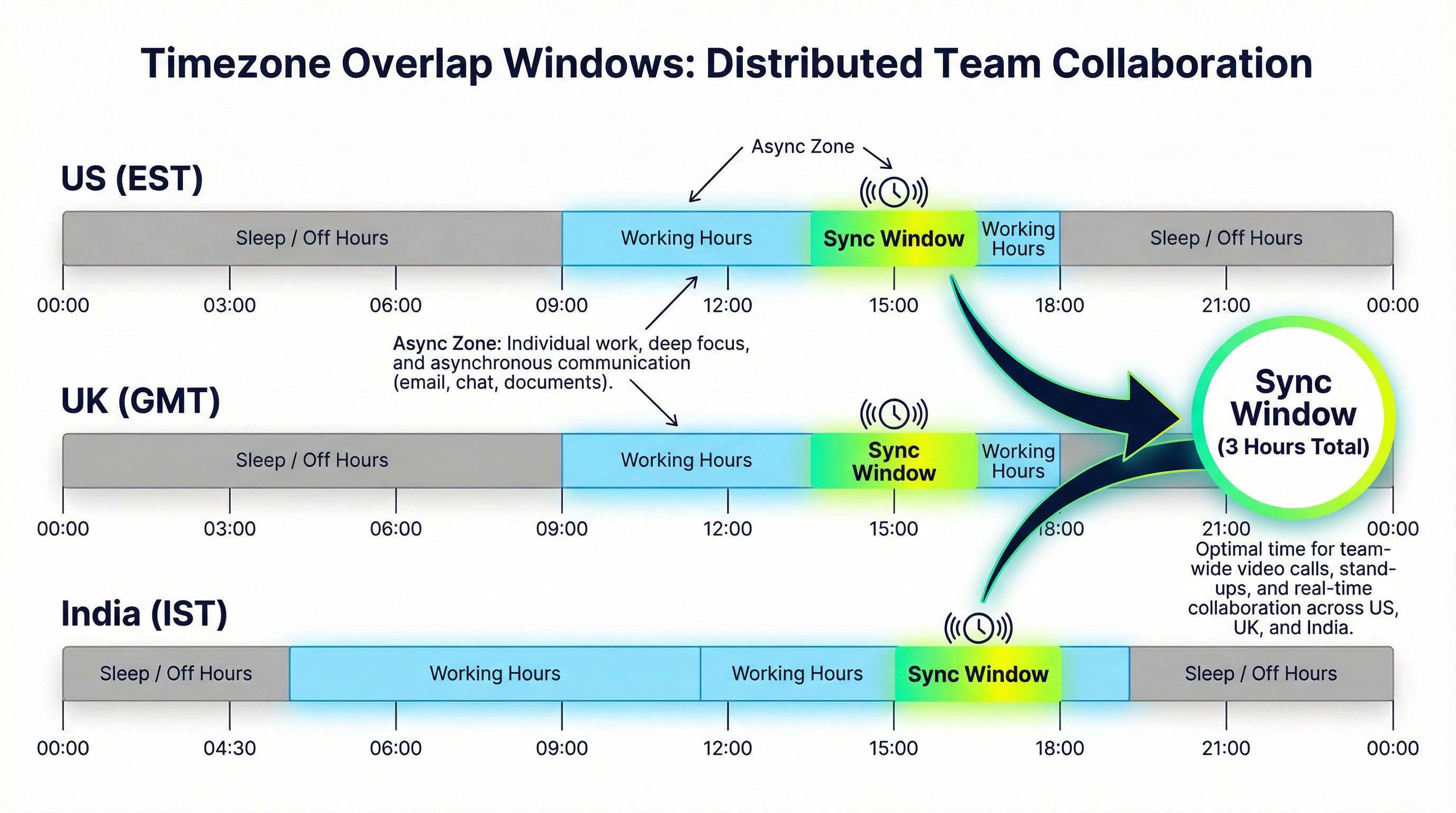
The overlap window: how to use it well
For a US East Coast / Mumbai pairing, the overlap window is roughly 8:30-11:30am EST (6pm-9pm IST). For UK / Mumbai, it's around 12pm-5pm GMT (5:30pm-10:30pm IST). This window is precious. Most distributed teams waste it on things that could have been async.
The overlap window should be protected for:
- Decisions that require real-time back-and-forth — architectural choices, scope questions, prioritisation calls where the conversation itself generates the answer.
- Relationship-building — the informal conversation that builds trust and makes async communication work better. A 15-minute weekly check-in between tech leads across timezones is worth more to long-term team cohesion than most engineering processes.
- Unblocking — when someone is genuinely stuck and needs a quick answer to proceed, the overlap window is when that gets resolved.
- Sprint planning and retrospectives (per the above).
What the overlap window should not be used for: status updates (that's what async standups are for), things that could be reviewed asynchronously, and recurring check-ins that don't actually produce decisions.
Documentation as your asynchronous teammate
In co-located teams, a new engineer can walk over to someone and get 10 years of context in 20 minutes. In distributed teams, that's not possible — which means documentation isn't optional. It's load-bearing infrastructure.
The documentation that matters most for distributed teams isn't formal wikis or comprehensive specifications. It's the lightweight, just-in-time documentation that lives close to the work:
- Decision records — brief documents (ADRs) that capture the context, options considered, and rationale for significant technical decisions. When a question comes up six months later, the answer is findable without asking someone.
- Runbook per service — what does this service do, how do you run it locally, what breaks it, how do you debug the most common issues.
- PR descriptions (as covered above) — context that lives in the git history and is findable forever.
- Incident postmortems — what happened, why, how it was fixed, what changes prevent recurrence. Essential for a distributed team where not everyone is online during an incident.
None of this requires a documentation culture built overnight. Start with the decision record and the runbook. The habit compounds.
“The teams we've seen consistently ship well across timezone gaps are almost always teams with better engineering hygiene than their co-located counterparts. The constraint forces the discipline. The discipline becomes the advantage.
What this looks like with an InfAI Mumbai-based dev team
The playbook above is what we implement with every software development team we build. Before a client's Mumbai engineers write their first line of code, we align on: the branching strategy and PR size conventions, the review SLA and ownership model, how standups and planning will run, and what the documentation baseline looks like.
This isn't something we hand off to clients to figure out. We've built distributed development teams enough times to know which process decisions matter most and what the failure modes look like when they're skipped. The first two weeks are largely about getting the foundations right — and it's the investment that determines whether the team hits full velocity in month two or is still struggling with coordination overhead in month six.
The specific overlap window for a US-based client working with a Mumbai team is typically US morning / India evening. We structure onboarding, planning, and daily check-ins around that window, and build the async-first habits for everything else. Within 4-6 weeks, most teams find the distribution to be unremarkable — not because the timezone gap disappeared, but because the process stopped treating it as a problem.
If you're evaluating offshore software development and wondering how to make distributed engineering actually work — not just in theory but in daily practice — we'd enjoy the conversation. We can show you specifically how we've structured this for teams at different scales and in different timezone configurations.
FAQs
More than zero, less than you think. For most engineering teams, 2-3 hours of daily overlap is sufficient if async workflows are well-designed. Below 2 hours, you start to see meaningful friction — decisions stall, blockers sit longer, and relationship-building becomes harder. Above 5 hours of overlap, you're often replicating a co-located culture in distributed form, which creates different problems.
Less important than the culture, but for what it's worth: Slack or Linear for async communication and tickets, GitHub or GitLab with strong PR templates, Loom for async video (useful for explaining complex changes), and a simple decision record template in Notion or Confluence. The tool choice matters far less than the discipline around how information gets written down and shared.
This is one of the areas where timezone distribution is genuinely an advantage: follow-the-sun on-call means your production coverage improves rather than degrades. The requirement is clear runbooks, well-defined escalation paths, and postmortem culture so that every incident makes the next one easier to handle. We help clients build these before the first incident, not after.
With the right process foundations in place from the start: 4-6 weeks to be running smoothly, 2-3 months to be at full velocity. The single biggest factor is how much time is invested in the first two weeks — getting the workflows, communication patterns, and documentation habits established before the team is deep in feature delivery. Teams that skip this to "move fast" routinely spend months 2-4 unlearning bad habits.
Most of it does. The specific tools differ, but the underlying principles — async-first, small handoff units, explicit context, protected overlap windows — apply to any distributed function. Design reviews work better with async annotation tools than with sync calls. Analytics handoffs need clear documentation of data sources, assumptions, and methodology. The cultural shift is the same.
We treat process setup as part of the engagement, not something the client figures out on their own. Before engineers start, we run a brief alignment session with the client's technical lead to agree on branching strategy, PR conventions, review SLAs, standup format, and documentation standards. We then actively reinforce these patterns in the first weeks through code review feedback and retrospectives. Most clients find this makes the difference between a distributed team that needs constant management and one that runs independently.
Build Your Team, Not Just a Contract
With InfAI's offshore dedicated teams, you get professionals who join your workflow for the long run. Grow steadily, stay flexible, and work with people who care about your success as much as you do.